
[English version only]
Some months ago, my colleague Florian and me joined a development team of one of our clients. We are involved as architects and engineers of the application used in their retail stores.
The client currently migrates the core software from running decentralized in each retail store (with its own databases) to a central solution. They heavily invested in Microsoft Azure as a Cloud provider and are moving more and more workloads to the Azure Cloud.
The client currently uses MSSQL databases in combination with the open-source Firebird database and has started to migrate data into the cloud. They have decided to use Cosmos DB as standard database for all new services in the cloud some years ago as it was the cheapest choice from their point of view.
![]()
![]()

What is Azure Cosmos DB?
Azure Cosmos DB is the solution of Microsoft for fast NoSQL databases. For those who live in the AWS (Amazon Web Services) world, Cosmos DB can be compared to the service DynomoDB. You can learn more about Cosmos DB here: https://azure.microsoft.com/en-us/products/cosmos-db
Source: https://azure.microsoft.com/en-us/products/cosmos-db
When working with Cosmos DB, you have to forget all the things you learned in the relational database world. To design a good data model, you need to learn how to design a data model depending on your future access patterns to your data, because the performance of Cosmos DB depends on the partitions. Therefore you must put more effort into the data modelling upfront. You can find more about here: https://learn.microsoft.com/en-us/azure/cosmos-db/nosql/modeling-data
Cosmos DB instances can be created on demand and can be used in many programming languages.
The unique point of Cosmos DB – in comparison to traditional relational databases – is the distribution of the stored data around the world, the on-demand scalability and the effortless way to get data out of it. Due to the ensured low response times Cosmos DB allows multiple use cases in the web, mobile, gaming and IoT applications to handle many reads and writes.
Further use cases can be found here: https://learn.microsoft.com/en/azure/cosmos-db/use-cases
Having joined the project as an architect and engineer, I was critical of using Azure Cosmos DB from the start, as I am a big fan of relational databases, especially for transactional data. My Cosmos DB journey began with writing a centralized device service to store clients’ purchased devices. We have used Azure Functions to implement the business logic on top of Azure Cosmos DB to retrieve and store the data.
Structure of Azure Cosmos DB
Microsoft allows their customers to create several Cosmos DB instances in one Azure tenant. You can compare it to a database which holds several database tables. These instances can be used to separate workloads for different teams, stages or use cases.
Within these instances we manage cosmos containers (aka “cosmos collections). It depends on the use case and structure how to split these containers.
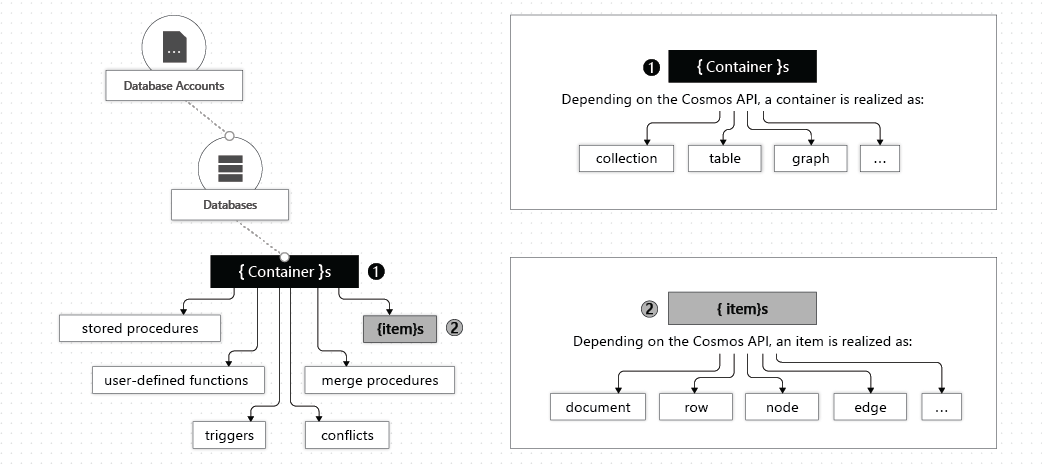
There are other elements in the overview like user-defined functions or triggers which are not part of this blog post.
The data is stored in multiple partitions and a document is stored based on the provided partition key in a specific partition. There are restrictions on how much data can be stored in a partition. Best practices and limitations around partitions and partition keys are advanced topics and are not part of this blog post.
Coming back to the data model an example item for a device looks like this:
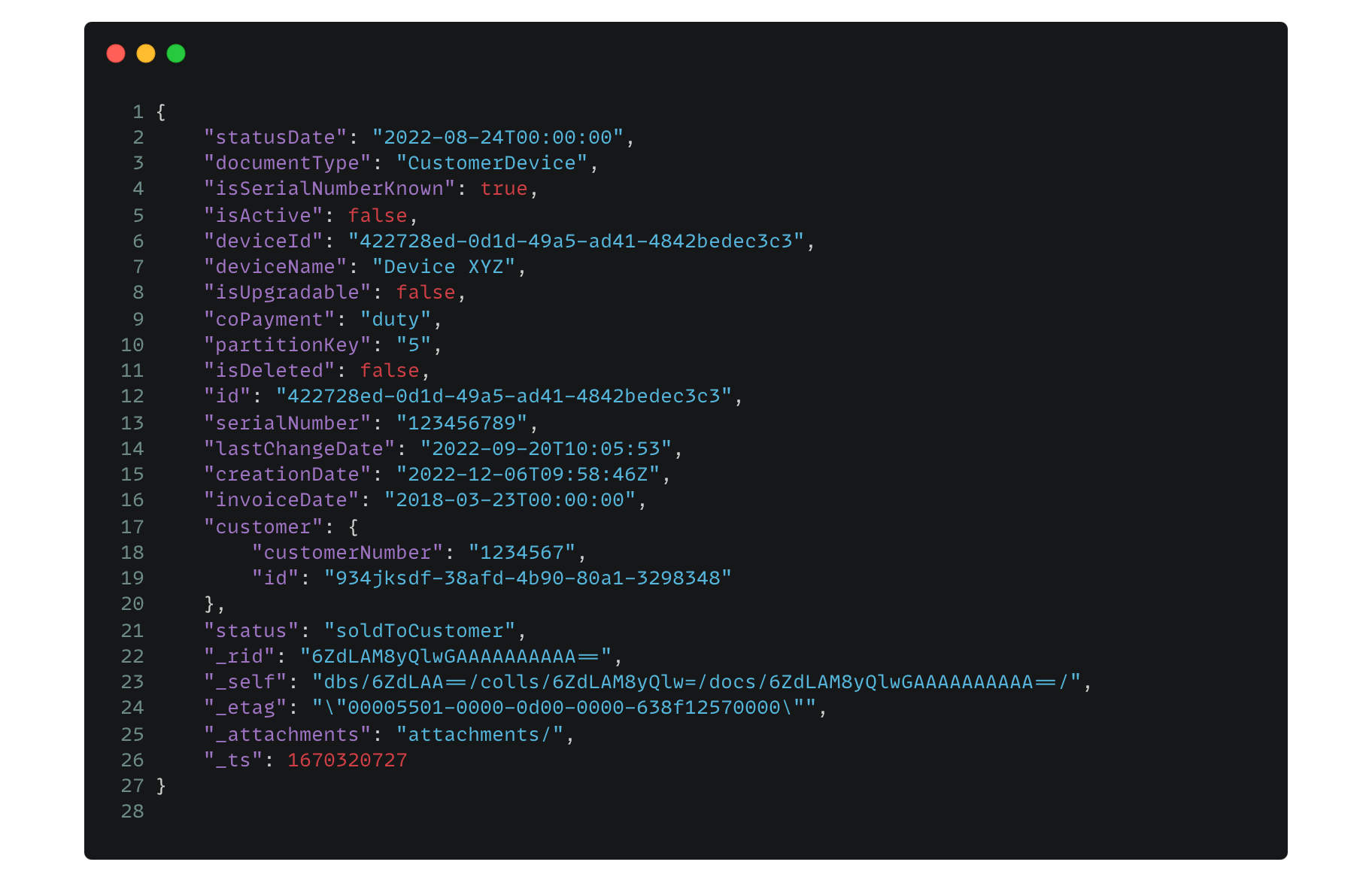
Of course, in the document database world you can model your data without a specific schema. You can create your own JSON structures which makes it flexible as well. Often the idea is to combine different data into one item to allow fast reads. To reference data in other domains, you can use unique identifiers like the property id in the customer object.
You can find more about the structure of Azure Cosmos DB here: https://learn.microsoft.com/en-us/azure/cosmos-db/account-databases-containers-items
Accessing data
Azure provides multiple ways to query data from Azure Cosmos DB.
The following interfaces are possible:
- NoSQL API
- MongoDB API
- Cassandra API
- Gremlin API
- Table API
An overview can be found here: https://learn.microsoft.com/en-us/azure/cosmos-db/choose-api
We started to use the NoSQL API in our project with the SQL like interface. It was an easier migration path coming from SQL based relational databases in comparison to the other interfaces. To access the data, you can also use the Azure Portal with the Data Explorer – the data explorer allows you to access your collections, query and manipulate data.
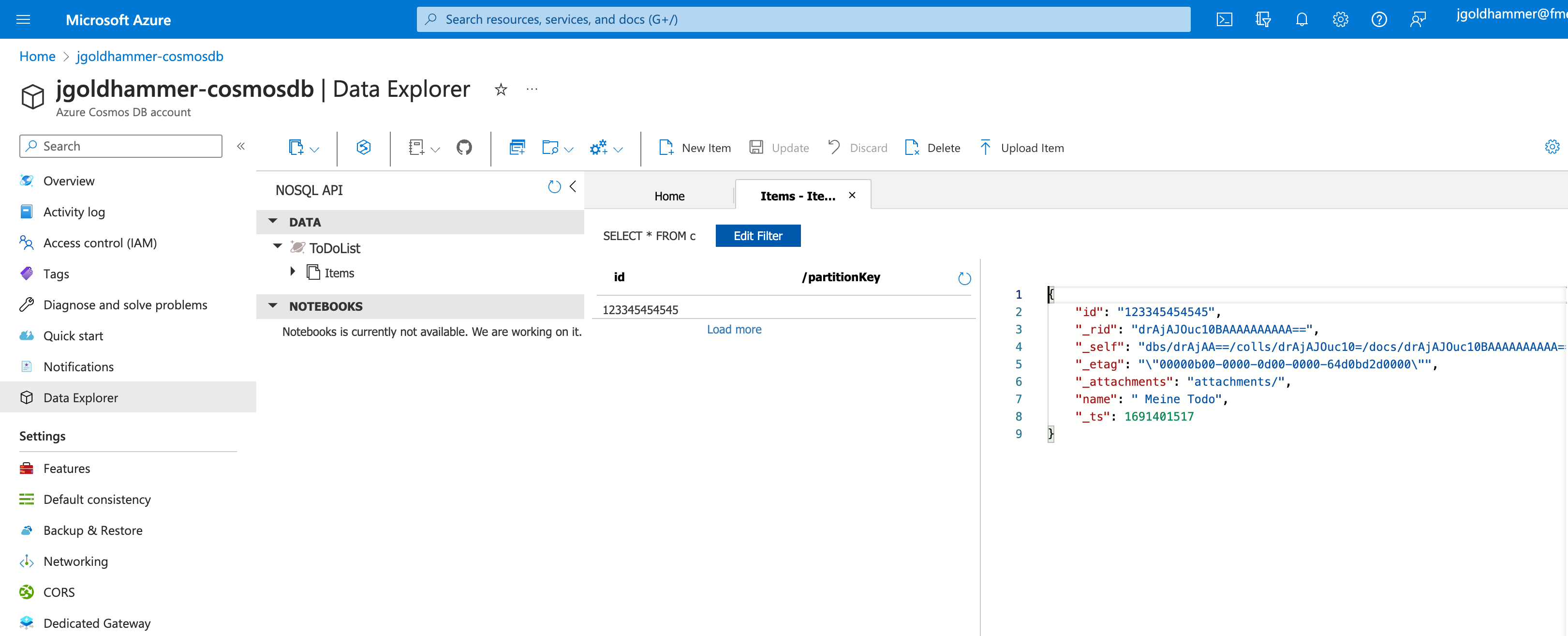
Migration / Import mass data
Cosmos DB allows to import data flexibly with different APIs.
There are two options at the moment:
- Import via Azure Datafactory service which can be used out of the box
- Import via custom CLI Tool which uses the cosmosDB API -> this tool needs to be developed
One way to import mass data is via Azure Data Factory which allows to pipeline data and map data from various sources and import into a Cosmos DB collection. We have used this mechanism a lot to transfer data from on-premises relational databases into the cloud and migrate data via pipelines into Cosmos DB collections.
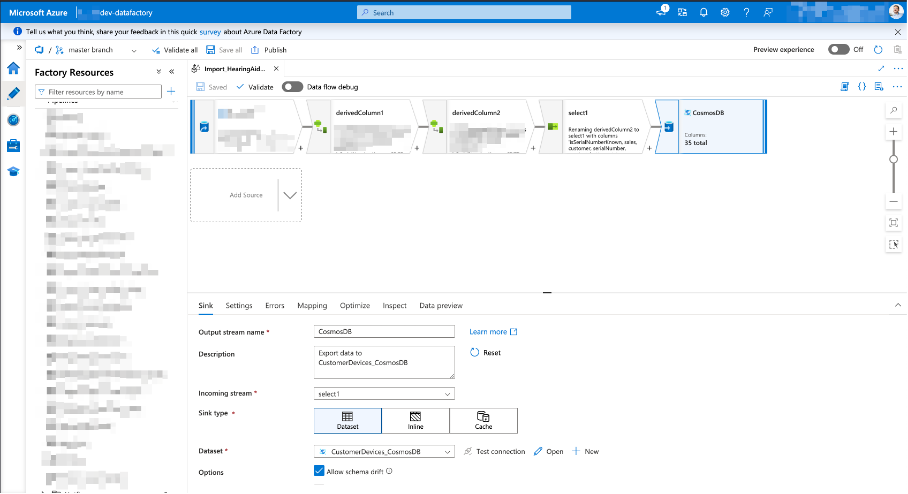
Source: Azure Portal example pipeline
Azure Data Factory works quite well, is fast and very flexible, but has its own drawbacks and challenges. Unfortunately, this topic is a subject in itself, so we cannot go into more detail here.
In the past we have also written our own CLI tools; they are more flexible for the datamapping and can be reviewed easier by other team members. By using bulk import with parallel threads with the cosmos API you will be as fast as the importing data via Azure Datafactory.
You can find a list of available SDKs here: https://developer.azurecosmosdb.com/community/sdk
Querying data
Azure Cosmos DB provides several APIs to retrieve the data out of the containers. We have decided to use the SQL interface to get data out in the used Azure functions.
You can for example take this SQL like query to select all devices of a customer.

This looks familiar, right?
After some time, you notice that the SQL capabilities are limited as Azure Cosmos DB implements only a limited set of SQL specifications:
- Cosmos DB does not allow to join items from different collections – it only allows to join the item with itself which means that you need to read data separately from different collections to join your data. The documentation says that you have to change your data model if you have needs for joining.
- Cosmos DB provides functions as well, but you may know only a few of them and sometimes in a completely different way as you may know from SQL. You have to learn the cosmos specific syntax as there is no standard for querying data in NoSQL databases.
- Cosmos DB has limited capabilities for the group-by with having clause. Sometimes there are workarounds, sometimes not.
- Cosmos DB supports Limit and Offset, but this is very slow (as it is implemented) and you should use continuation tokens instead. Why? If you are interested to understand this, read here: https://learn.microsoft.com/en-us/azure/cosmos-db/nosql/query/offset-limit and https://stackoverflow.com/questions/58771772/cosmos-db-paging-performance-with-offset-and-limit
My experience was that you often found good workarounds or a complete cosmos specific way, but sometimes you didn’t find a solution which was a little bit frustrating.
Nevertheless, the most painful issue was that CosmosDB only report errors with following message: “One of the input values is invalid.” in your query without a useful hint.
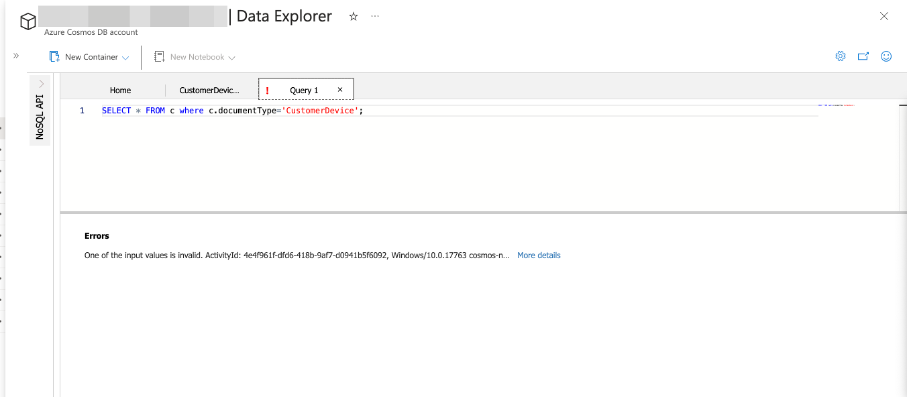
In this case, I made the mistake of putting a semicolon at the end of the query.
Updating data
Updating one or multiple rows in a relational database with one SQL statement is a common request for processing data.
Azure Cosmos DB exactly allows to update one item within a container by using multiple requests.
The procedure looks like this:
- Retrieve the whole document you want to update
- Update the fields you want to update in your application code
- Write back the whole document to Cosmos DB
Microsoft provides a new SQL update API to update one item without reading it before. The syntax for updating data is driven by the JSON PATCH standard (https://jsonpatch.com). This feature was a long time in preview and now is generally available in Azure Cosmos DB.
Mass updates to a larger set of documents cannot be done out of the box with one SQL statement. You must update each document separately. This limitation is a little bit surprising when you want to evolve your document schema.
Yes, you can write a tool based on the bulk API. But you probably know that updating a lot of data is slow and involves much more effort instead of writing a single update query like in the relational data world.
Deleting data
Deleting data in Azure Cosmos DB is generally possible by removing one item at a time via API. But there is unfortunately no support for SQL Delete-Statements!
In general all limitations for mass operations in Cosmos DB may have reasons – for instance, the guaranteed response times for any action in the Cosmos DB. Operations on a bigger set of data might lead to higher execution times.
But indeed this is an annoying point while writing and testing your software. Sometimes you need to remove specific data very quickly. One workaround is to drop the whole container and create your test data again, but often you have the case that you want to keep specific data in it.
For example, we had to remove two million entries from a collection to repeat a migration, but wanted to keep other data in the collection. This action took half an hour by using a developed tool.
Transactions
Azure Cosmos DB provides a simple transactional concept. It allows to group a set of operations in a batch operation. Unfortunately, the batch concept is not integrated nicely into the API as it does not allow to wrap your code into a transactional block like interfaces to relational databases allow.
Additionally, transactions do not allow to update documents from different partitions which is understandable from a technical point of view, but this limits a lot. In our service we had the use case to update several documents at once from several partitions and we had to live without transactions in the end.
Ecosystem & Community
I was very surprised starting with Cosmos DB to find such limited resources, articles and tools around the platform. But I understood this situation quickly because Cosmos DB is an exclusive, commercial service of Microsoft and is not as popular as Amazon DynomoDB for example.
Microsoft itself provides limited tooling only:
- the azure portal with the data explorer https://cosmos.azure.com
- a visual studio code extension https://marketplace.visualstudio.com/items?itemName=ms-azuretools.vscode-cosmosdb
- a CosmosDB emulator which runs natively under Windows https://learn.microsoft.com/de-de/azure/cosmos-db/data-explorer
The community has written some tooling:
- The Cosmos DB Explorer for Windows https://github.com/sachabruttin/Cosmos DBExplorer
- CosmicClone to clone data from one container to another (https://github.com/microsoft/CosmicClone)
Unfortunately there is no big community around Cosmos DB like for example for PostgreSQL or MySQL/MariaDB. Anyways, most of the good, known database tools out there which are supporting several vendors do not support Azure Cosmos DB. Mostly because it works completely different than relational databases.
Advanced topics
Additionally Azure Cosmos DB allows to use stored procedures. Wait – Are stored procedures not a thing from the last century? Why should we use it? Probably you will notice that you need to use stored procedures for some scenarios like a mass deletion of entries in your collection as this is not supported out of the box.
Writing stored procedures is supported in Cosmos DB with JavaScript. As you may know, testing becomes challenging for this kind of code and besides that, most of the backend developers in our team are not familiar with JavaScript. Due to these challenges, we decided not to use them within the application apart from administrative purposes!
There are many advanced topics for Cosmos DB like scaling, partition keys etc. – these topics need their own blog post. You can read more about that in the official documentation: https://learn.microsoft.com/en-us/azure/cosmos-db/
Summary
Using a document-based database is not a no-brainer. Document-based databases like Azure Cosmos DB are not a replacement for relational databases and it was never the intention.
Yes, Azure Cosmos DB has its use cases:
- If you have the use case “write once – read many” (for example just store data with a stable structure), you can use it.
- If you need global distribution of your data, you probably need it.
The problem is that you do not have these requirements in general for business applications very oftem. In my opinion most of the applications do not need to scale this way (besides, you are Amazon, Microsoft, Netflix or another global player).
On the other side Azure Cosmos DB has some heavy limitations when working with the data, especially if you want to evolve your schema. If you want to store relational data within Cosmos DB and have a lot of changes in the data over time, Cosmos DB makes it very complicated and is currently not a good choice from my point of view.
Besides these considerations one task has become very, very important from the beginning: design how to model and to partition your data. But this is a story on its own.
Resources
https://medium.com/@yurexus/features-and-pitfalls-of-azure-cosmos-db-3b18c7831255
https://mattruma.com/adventures-with-azure-cosmos-db-limit-query-rus/
https://blog.scooletz.com/2019/06/04/cosmosdb-and-its-limitations/




0 Kommentare