
Introduction
According to a recent Gartner research, 52% of enterprises plan to invest in a data lake within the next two years.1
The purpose of a data lake is to collect data from different sources without having any limitations. For instance, the data can be in raw format, and no structure is required. Besides, there are data pipelines processing, enriching, and transforming the data into a structured form. Other enterprise systems can have access to the structured data and visualize the results.
AWS supports the creation of data lakes by providing various services. These services are shown below in their respective domains:
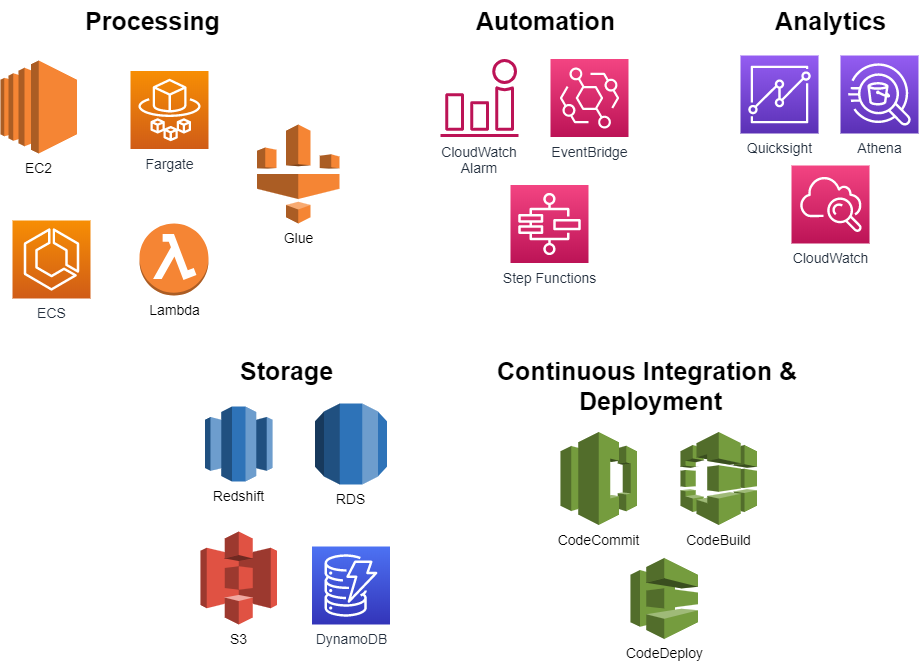
Figure 1 – AWS Services for Data Lakes
Of course, data lakes produce increasing monthly costs as every cloud service does. In 2021 enterprise companies expect a 39% increase in cloud spendings.2
Most companies struggle to understand the total cost of IT services in the cloud. That leads to a substantial proportion of 30% waste of the IT budget spend in 2021. 2
To keep the cloud costs in control, it is essential to focus on cloud cost management at the beginning of the project. The following part describes a few examples of identifying the optimal AWS services for your data lake and making the configuration as efficient as possible.
Data storage optimization
Most data lakes utilize S3 for the raw data storage. The most expensive S3 storage class, S3 Standard, is configured as default. It is designed for 99.999999999% durability and is optimal for frequently accessed data. In most data lake projects data in S3 is uploaded which may automatically trigger the processing of the data which structure the data and store it in a data warehouse. Thereafter, the data in S3 is usually archived and rarely accessed again.
Simple cost optimization is to set the storage class to S3 Intelligent-Tiering instead of S3 Standard. By applying this, AWS automatically chooses the optimal storage class for each data set based on the historical access frequency. The storage cost savings can be up to 80% depending on the data access frequency.
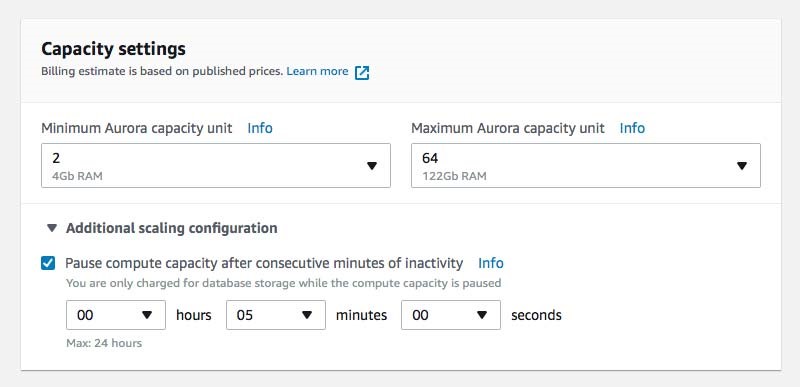
Figure 2 – RDS Aurora Serverless Scaling Configuration
Data Processing optimization
After uploading the raw data, a data processing step analyzes and converts the data into structured form. A popular choice is to build a serverless and event-driven architecture for data processing. Typically, this involves Lambda functions that are processing new raw data is uploaded automatically. But Lambda is only an option for short-running tasks not longer than 15 minutes. For compute-intensive and long-running processing tasks, consider using Fargate as a serverless and cheaper option than paying full-time for an EC2 instance. Implementing a serverless architecture can save up to 70% of processing costs.
Database optimization
The data processing step may utilize a database to store data in a structured form. A database as storage performs best when the data needs to be filtered and retrieved regularly. One common use case for a database in data lake projects is defining a view with given filters that provides an interface for another enterprise target system. AWS RDS is the most common database service that supports multiple database engines like MySQL or PostgreSQL. Until late 2018 the only option was to configure provisioned EC2 instances to host the selected database cluster. Since then, there is another option for MySQL and PostgreSQL databases called Aurora Serverless. It is now possible to define capacity boundaries for your database within AWS automatically scales up and down depending on the current usage. Optionally, the database can even pause completely when the database is not in use (think of the nighttime when no developer or user traffic occurs). In this case, AWS charges for storage only, which can save up to 75% of your database costs.
Automation
A well-designed data lake architecture should aim to automate as much as possible. The following architecture diagram illustrates a data lake that utilizes AWS step functions and AWS EventBridge for automation.
The whole workflow intends to convert the raw data into a structured and enriched form and write it into an RDS Aurora database (called ‘Silver Zone’).
The start point builds the S3 bucket where connected source systems upload raw data regularly. A new upload notifies an AWS EventBridge rule which triggers the AWS step function workflow. The AWS step function consists of multiple Lambdas that validate the uploaded file content, process and transform the files, and create a backup of the silver database. The silver database contains critical data with production use, so completing the backup is mandatory before writing new data. Because the data processing requires 32GB of RAM and takes longer than 15 minutes, a Fargate container in an ECS cluster is triggered instead of a Lambda that writes the structured data into the silver database. Also, the Fargate container includes data enrichment from another system.
Automation reduces manual effort and human errors that most likely result in saving a big chunk of the project budget.
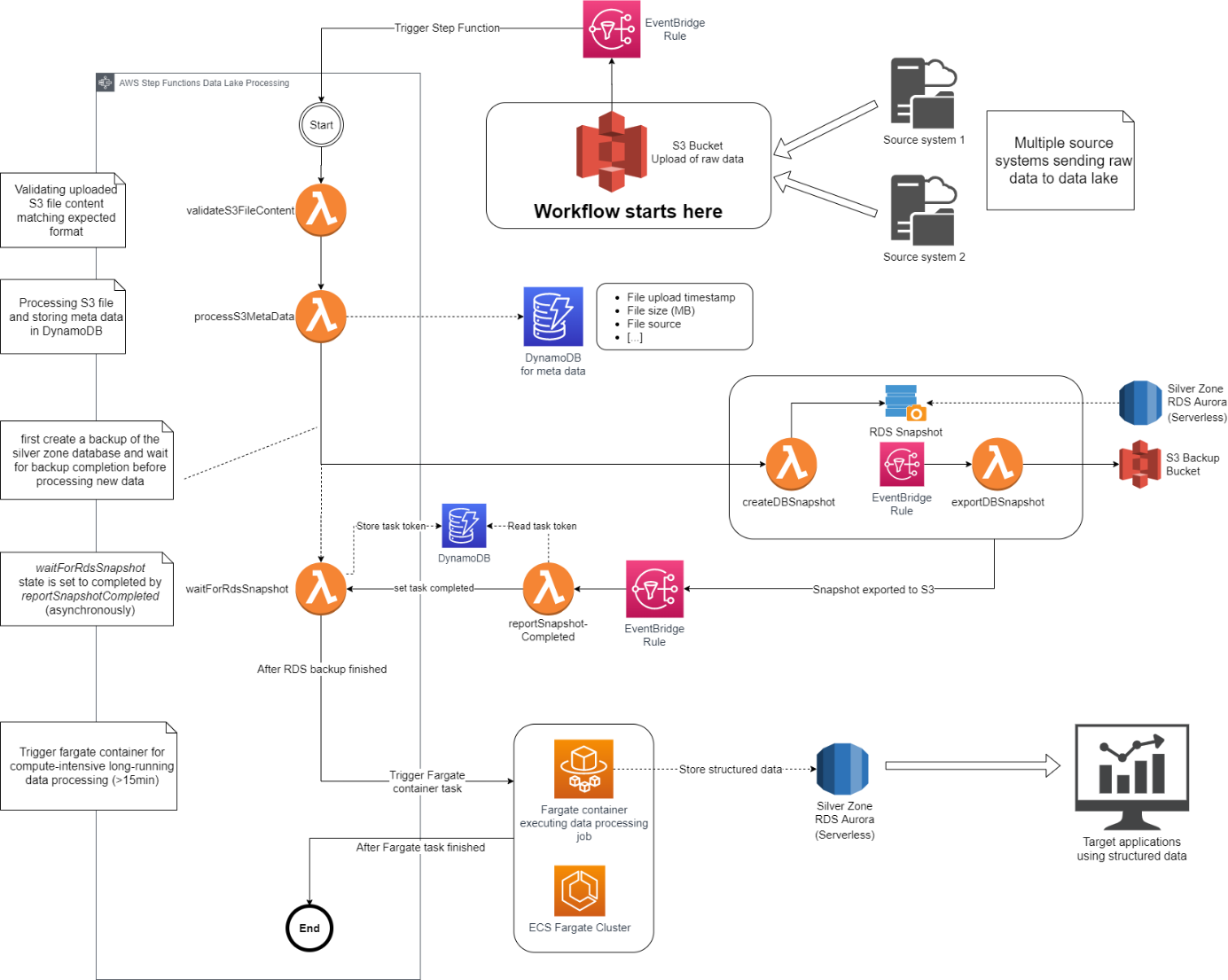
Figure 3 – Data Lake Architecture Using Automation



0 Comments