Der wohl offensichtlichste Schritt um die Kosten zu senken, ist das Löschen ungenutzter Ressourcen wie brachliegender EC2- oder RDS-Instanzen, alter EBS-Snapshots oder AWS-Backup-Dateien usw. Ein weiterer Ansatzpunkt zur Kostenreduzierung sind S3-Buckets, die große Mengen an alten oder ungenutzten Daten enthalten.
Abgesehen davon, dass sie kein Geld verschwenden, erhöhen all diese Maßnahmen gleichzeitig die Sicherheit: Was nicht mehr verfügbar ist, kann nicht gehackt werden oder nach außen dringen. AWS bietet Funktionalitäten wie AWS Backup/S3-Aufbewahrungsrichtlinien für die automatische Verwaltung des Datenlebenszyklus, die den manuellen Aufwand reduzieren.
AWS Saving Plan
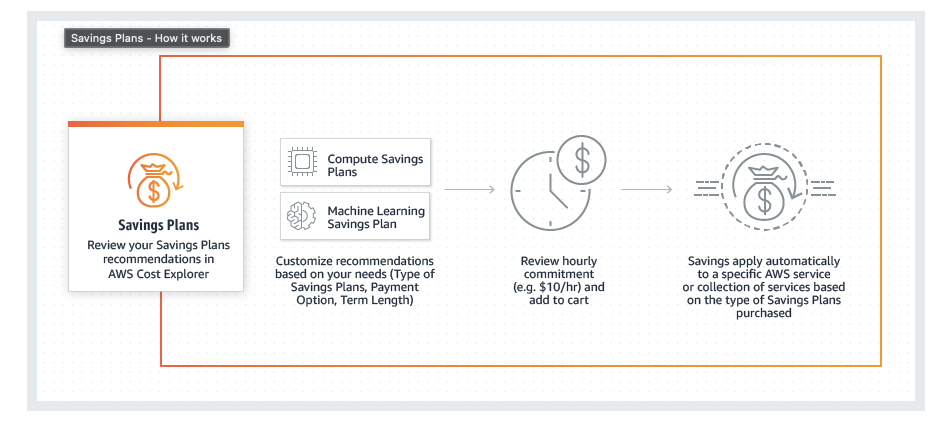
Die AWS Saving Plans oder Sparpakete, die es in verschiedenen Varianten gibt, wurden vor etwa 3 Jahren eingeführt. Sie bieten Preisnachlässe von bis zu 72 Prozent im Vergleich zu den On-Demand-Preisen, sofern man den “EC2 Instance Savings”-Plan wählt. Besonders der flexiblere “Compute Savings Plan”, der immer noch bis zu 66 Prozent Rabatt bietet, ist sehr attraktiv, da er nicht nur EC2, sondern auch Lambda und Fargate abdeckt.
Vor allem Workloads, die rund um die Uhr laufen und deren Auslastung einigermaßen vorhersehbar ist, eignen sich für solche Angebote. Je nach gewählter Laufzeit (1 oder 3 Jahre) und Zahlungsoption (No, Partial oder All Upfront) wird ein fester Rabattsatz für die Beauftragung eines bestimmten Dollarbetrages pro Stunde für Rechenleistung gewährt. Architektonische Änderungen wie der Wechsel von EC2-Instanztypen oder die Verlagerung von Arbeitslasten von EC2 zu Lambda oder Fargate sind möglich und im Rahmen der Compute Savings Plans abgedeckt.
Sparpakete zu erwerben, ist ohne großen Aufwand möglich und führt zu beträchtlichen Einsparungen, zumal die meisten Workloads eine Art von Rechenleistung erfordern, die erheblich zu den Gesamtkosten beiträgt.
Reserved Instances und Reserved Capacity
Leider bietet AWS keine Sparkonzepte für alle potenziellen Szenarien oder AWS-Services an, jedoch gibt es andere attraktive Rabattoptionen wie Amazon RDS Reserved Instances, die Abhilfe schaffen. Reserved Instances nutzen vergleichbare Konfigurationsoptionen wie die Sparpakete und versprechen einen ähnlichen Rabattsatz für Workloads, die permanent laufende Datenbankserver erfordern.
Die Flexibilität bei Änderungen ist jedoch begrenzt und hängt von der verwendeten Datenbank ab. Nichtsdestotrotz lohnt es sich, Reserved Instances als eine Option zur Kostenoptimierung in Betracht zu ziehen, da auch hier nur ein minimaler Zeitaufwand erforderlich ist.
Amazon DynamoDB, die serverlose NoSQL-Datenbank, bietet eine Funktion namens Reserved Capacity. Sie garantiert eine bestimmte Menge an Lese- und Schreibdurchsatz pro Sekunde und Tabelle. Auch hier gelten ähnliche Laufzeiten und Zahlungsbedingungen wie bei den zuvor erwähnten Sparplänen und Reserved Instances. Bei prognostizierbaren Datenübertragungsraten reduzieren sich im Vergleich zu den Durchsatzmodi On-Demand oder Provisioned die Kosten deutlich.
Automatisches Herunterfahren und Neustart von EC2- und RDS-Instanzen
Viele EC2- und RDS-Instanzen werden nur zu bestimmten Tageszeiten und am Wochenende oft überhaupt nicht genutzt. Dies gilt vor allem für Entwicklungs- und Testumgebungen, kann aber auch für den Produktionsbetrieb zutreffen. Durch das Abschalten dieser nicht benötigten Instanzen lassen sich beträchtliche Summen einsparen.
Ein automatisierter Ansatz, der das Herunterfahren und den Neustart nach einem Zeitplan initiiert und verwaltet, kann diese Aufgabe übernehmen, so dass fast keine manuellen Eingriffe mehr erforderlich sind. AWS bietet eine Lösung namens “Instance Scheduler” an, die diese Arbeit übernehmen kann, sofern keine bestimmte Start- oder Shutdown-Logik für eine Anwendung befolgt werden muss.
Spezifische Arbeitsabläufe, die z. B. erfordern, dass zuerst die Datenbanken gestartet werden, bevor irgendwelche Server hochgefahren werden, lassen sich mit AWS Step Functions modellieren und über geplante EventBridge-Regeln ausführen. Step Functions ist extrem leistungsfähig und unterstützt eine Vielzahl von API-Operationen, so dass nahezu kein eigener Code benötigt wird.
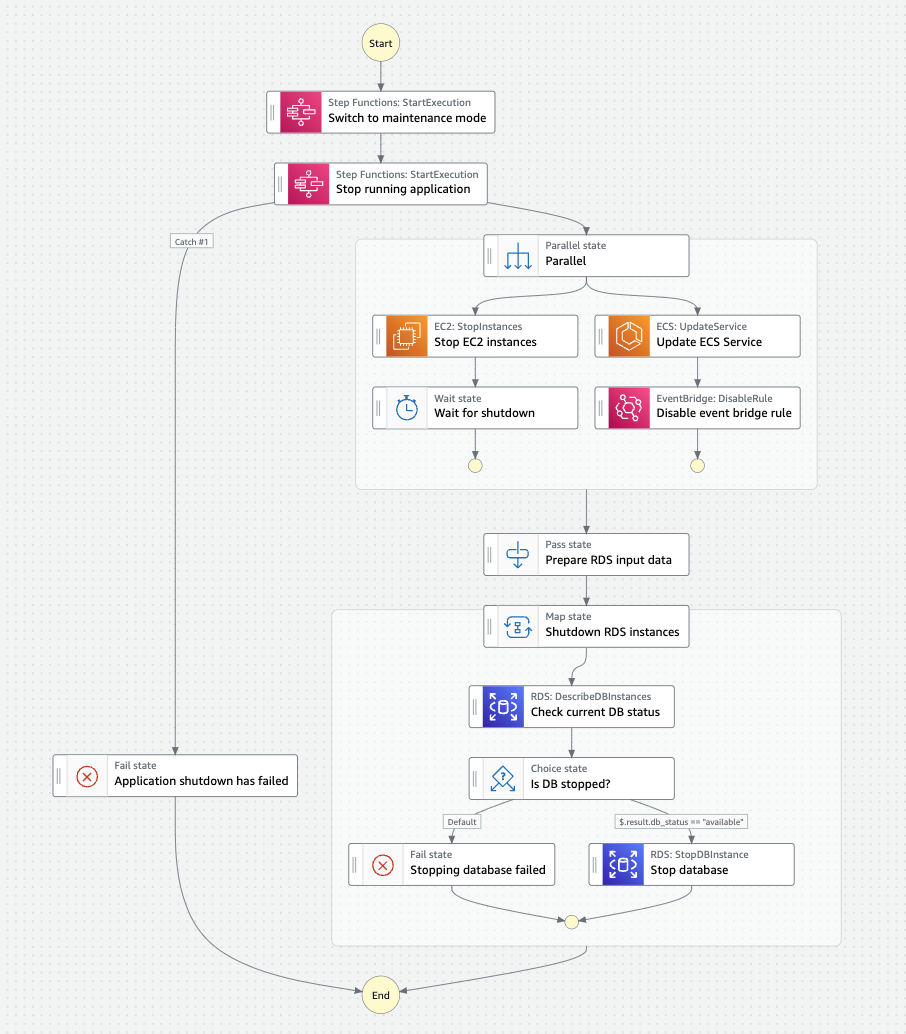
Ein Beispiel für einen echten Arbeitsablauf, bei dem eine Anwendung, die aus mehreren RDS- und EC2-Instanzen besteht, angehalten wird, ist in der folgenden Abbildung dargestellt. Es muss eine strenge Abfolge von Shutdown-Schritten eingehalten werden, um sicherzustellen, dass die Anwendung korrekt beendet wird. Dieser Workflow wird jeden Abend ausgelöst, sobald die Umgebung nicht mehr benötigt wird.
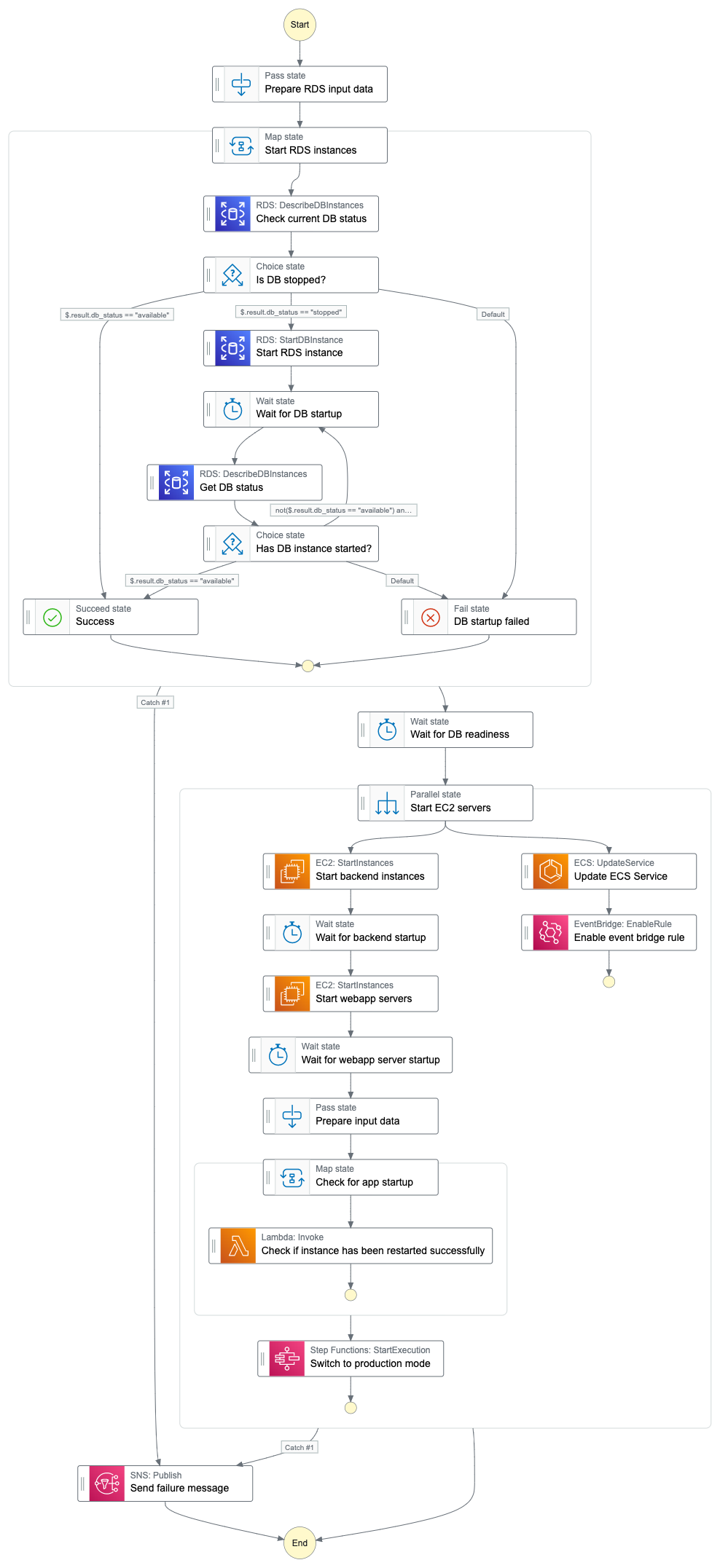
Das Pendant dazu finden Sie im nächsten Beispiel. Dieser Workflow wird verwendet, um die Umgebung jeden Morgen zu starten, bevor der erste Entwickler seine Arbeit aufnimmt.
Durch das Herunterfahren aller EC2- und RDS-Instanzen über Nacht und am Wochenende konnten die Rechenleistungskosten in diesem Projekt um etwa 50 Prozent gesenkt werden, und das ist für eine größere Umgebung erheblich. Der einzige Nachteil dieses Ansatzes war bisher eine unzureichende EC2-Kapazität, wenn man versuchte, die Instanzen am Morgen neu zu starten. Das ist zwar nur sehr selten vorgekommen, aber es dauerte etwa einen halben Tag, bis AWS genügend Ressourcen für einen erfolgreichen Neustart zur Verfügung hatte.
Hoch- und Herunterskalieren von Instanzen in Testumgebungen
Diese Option funktioniert allerdings nicht in allen Fällen, da Testumgebungen (auch bekannt als UAT-Umgebungen) häufig die produktive Arbeitslast widerspiegeln, um bei der Durchführung manueller oder automatisierter Tests nahezu identische Bedingungen zu schaffen. Insbesondere Lasttests, aber auch andere Tests sollten daher auf produktionsähnlichen Systemen durchgeführt werden, da ihre Ergebnisse sonst nicht zuverlässig sind. Außerdem läuft nicht jede Anwendung auf kleineren EC2-Instanzen so reibungslos wie auf größeren, bzw. kann eine Änderung der Instanzgröße zusätzliche Anpassungen der Anwendungskonfiguration erfordern.
Nichtsdestotrotz ist es manchmal möglich, die Instanzen herunter zu skalieren (RDS-Datenbanken könnten eine zusätzliche Option sein), sofern Last- und andere schwere Tests nicht regelmäßig durchgeführt werden (auch wenn dies theoretisch empfohlen wäre).
Mit Hilfe von Infrastructure-as-Code-Frameworks wie Terraform oder CloudFormation ist es relativ einfach, zwei Konfigurationssätze zu definieren. Diese können vor der Durchführung eines Lasttests ausgetauscht werden, um die Umgebung zu vergrößern. EC2 unterstützt Änderungen der Instanzgröße im laufenden Betrieb (kein Neustart erforderlich) und sogar einige RDS-Datenbanken lassen sich ohne Systemunterbrechung anpassen. Der gesamte Upscale- oder Downscale-Prozess nimmt nur wenig Zeit in Anspruch (abhängig von der Größe der Umgebung und den Instance-Typen) und kann zu erheblichen Einsparungen führen.
Gestaltung neuer Anwendungen mit einer Serverless-First-Mentalität
Serverless ist in den letzten Jahren zu einem Buzzword und Marketingbegriff geworden (“Alles scheint heutzutage serverless zu sein”), aber im Grunde ist es immer noch ein recht vielversprechender technologischer Ansatz. Die Befreiung von einer ganzen Reihe administrativer und operativer Aufgaben wie der Bereitstellung und dem Betrieb von virtuellen Servern oder Datenbanken, gepaart mit dem Modell, nur für das zu zahlen, was man nutzt, ist sehr verlockend. Weitere Vorteile von serverlosen Architekturen sollen in diesem Artikel nicht näher erörtert werden, sondern lassen sich leicht über Ihre bevorzugte Suchmaschine finden.
Insbesondere das “Pay as you go”-Kostenmodell trägt zur direkten Kostenoptimierung bei (wobei in diesem Beitrag Themen wie Gesamtbetriebskosten und Markteinführungszeit, die in der Praxis ebenfalls wichtig sind, nicht berücksichtigt werden). Es besteht keine Notwendigkeit, etwas herunterzufahren oder neu zu starten, wo es nicht benötigt wird. Serverlose Komponenten belasten Ihre AWS-Rechnung nicht, wenn sie nicht genutzt werden – zum Beispiel nachts in Entwicklungs- oder Testumgebungen. Auch produktive Arbeitslasten, die oft keinen konstanten, sondern eher einen punktuellen Datenverkehr verzeichnen, profitieren im Vergleich zu einer auf Containern oder VMs basierenden Architektur.
Nicht jede Anwendung oder Arbeitslast ist für ein serverloses Entwicklungsmodell geeignet. Der Fairness halber sollte erwähnt werden, dass ein serverloser Ansatz bei sehr starkem Datenverkehr deutlich teurer werden kann als ein auf Containern basierender Ansatz. Dies trifft jedoch wahrscheinlich nur auf einen sehr kleinen Teil aller bestehenden Implementierungen zu.
Es ist oft möglich und vorteilhaft, eine VM oder einen Container durch eine oder mehrere Lambda-Funktionen, eine RDS-Datenbank durch DynamoDB oder eine benutzerdefinierte REST/GraphQL-API-Implementierung durch API Gateway oder AppSync zu ersetzen. Die Lernkurve ist jedoch steil, und gut durchdachte Serverless-Architekturen sind anfangs nicht so einfach zu entwickeln, da ein kompletter Bewusstseinswandel erforderlich ist. Aber glauben Sie mir: Diese Reise ist die Mühe wert und macht einen Riesenspaß, sobald man einige Einblicke in diese Technologie gewonnen hat.
Überlegen Sie, was geloggt und an CloudWatch gesendet werden soll
Die Protokollierung (Logging) ist seit der Erfindung der Software ein wichtiger Bestandteil der Anwendungsentwicklung und des Betriebs. Nützliche Logdaten (hoffentlich in strukturierter Form) können helfen, Fehler oder andere Unzulänglichkeiten zu erkennen und einen nützlichen Einblick in ein Softwaresystem zu geben. Mit CloudWatch bietet AWS eine Plattform zur Erfassung, Speicherung und Analyse von Logs.
Leider ist die Verarbeitung von Logdaten recht kostspielig. Nicht selten ist der Anteil der AWS-Rechnung, der auf CloudWatch entfällt, bis zu 10 Mal höher als beispielsweise der von Lambda in serverlosen Projekten. Das Gleiche gilt für Container- oder VM-basierte Architekturen, wobei das Verhältnis vielleicht nicht ganz so hoch aber dennoch nicht zu vernachlässigen ist. Ein Konzept, wie man mit dem Log-Output umgeht, ist empfehlenswert und kann am Ende des Monats einen erheblichen Preisunterschied ausmachen.
Einige der folgenden Ideen helfen, die CloudWatch-Kosten im Griff zu behalten:
- Ändern Sie die Log-Aufbewahrungszeit von “Never expire” auf einen sinnvollen Wert.
- Wenden Sie Logstichproben an, wie in diesem Beitrag beschrieben und zum Beispiel von den AWS Lambda Powertools bereitgestellt
- Ziehen Sie die Verwendung eines Überwachungssystems von einem Drittanbieter wie Lumigo oder Datadog in Betracht, anstatt viele Lognachrichten auszugeben. Diese externen Systeme sind zwar nicht kostenlos und dürfen nicht immer verwendet werden (insbesondere in einem Unternehmenskontext), bieten aber viele zusätzliche Funktionen, die einen echten Unterschied machen können.
- In einigen Fällen ist es möglich, Protokolle direkt an andere Systeme zu senden (anstatt sie zuerst in CloudWatch aufzunehmen) oder sie in S3 zu speichern und Athena zu verwenden, um gewisse Erkenntnisse zu gewinnen.
- Aktivieren Sie Logging bei Bedarf und entsprechend, aber nicht immer in der Standardeinstellung – nicht jede Anwendung benötigt z. B. VPC-Flow-Protokolle oder API-Gateway-Zugriffsprotokolle, obwohl es in bestimmten Umgebungen (aus Sicherheitsgründen oder aufgrund bestimmter Vorschriften und Unternehmensregeln) dafür gute Gründe gibt.
Das Logging ist wichtig und in den meisten Fällen sehr nützlich, aber es ist sinnvoll, die Ausgaben im Auge zu behalten und das Protokollierungskonzept im Falle ausufernder Kosten anzupassen.
Zusammenfassung
Alle oben genannten Möglichkeiten zur Kostenoptimierung kratzen nur an der Oberfläche dessen, was im AWS-Universum möglich ist. Dinge wie S3- und DynamoDB-Speicherebenen, EC2-Spot-Instances und viele andere habe ich noch nicht einmal erwähnt oder erklärt. Nichtsdestotrotz kann die Umsetzung einer oder mehrerer der in diesem Artikel kurz besprochenen Strategien dabei helfen, eine Menge Geld zu sparen, ohne wochenlange Entwicklungszeit aufwenden zu müssen. Vor allem Savings Plans und Reserved Instances sowie das Abschalten ungenutzter Instanzen sind einfache und recht effektive Maßnahmen, um ihren Anteil an der AWS-Rechnung bei vorhandenen Workloads um 30 bis 50 % zu reduzieren. Neueste Workloads, die für das serverlose Designmodell geeignet sind, profitieren von dessen Kosten- und Betriebsmodell und machen Entwicklern richtig viel Spaß.






0 Kommentare